这种运行模式,和Local[N]很像,不同的是,它会在单机启动多个进程来模拟集群下的分布式场景,而不像Local[N]这种多个线程只能在一个进程下委屈求全的共享资源。通常也是用来验证开发出来的应用程序逻辑上有没有问题,或者想使用Spark的计算框架而没有太多资源。
用法是:提交应用程序时使用local-cluster[x,y,z]参数:x代表要生成的executor数,y和z分别代表每个executor所拥有的core和memory数。

上面这条命令代表会使用2个executor进程,每个进程分配3个core和1G的内存,来运行应用程序。可以看到,在程序执行过程中,会生成如下几个进程:
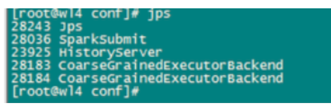
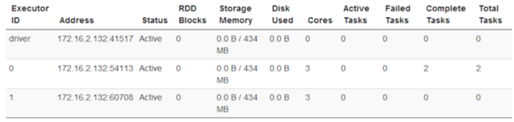
SparkSubmit依然充当全能角色,又是Client进程,又是driver程序,还有点资源管理的作用。生成的两个CoarseGrainedExecutorBackend,就是用来并发执行程序的进程。它们使用的资源如下:
运行该模式依然非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用。而不用启动Spark的Master、Worker守护进程( 只有集群的standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别哦,要记住才能理解。
转载自: 作者: 链接:https://www.jianshu.com/p/65a3476757a5 來源:简书